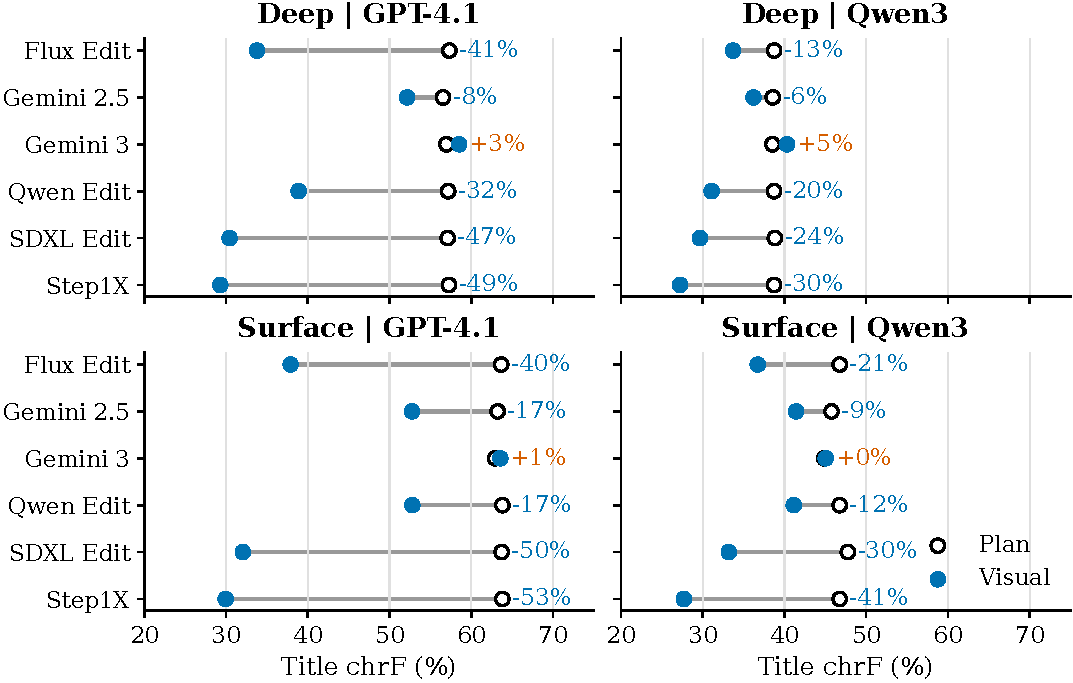
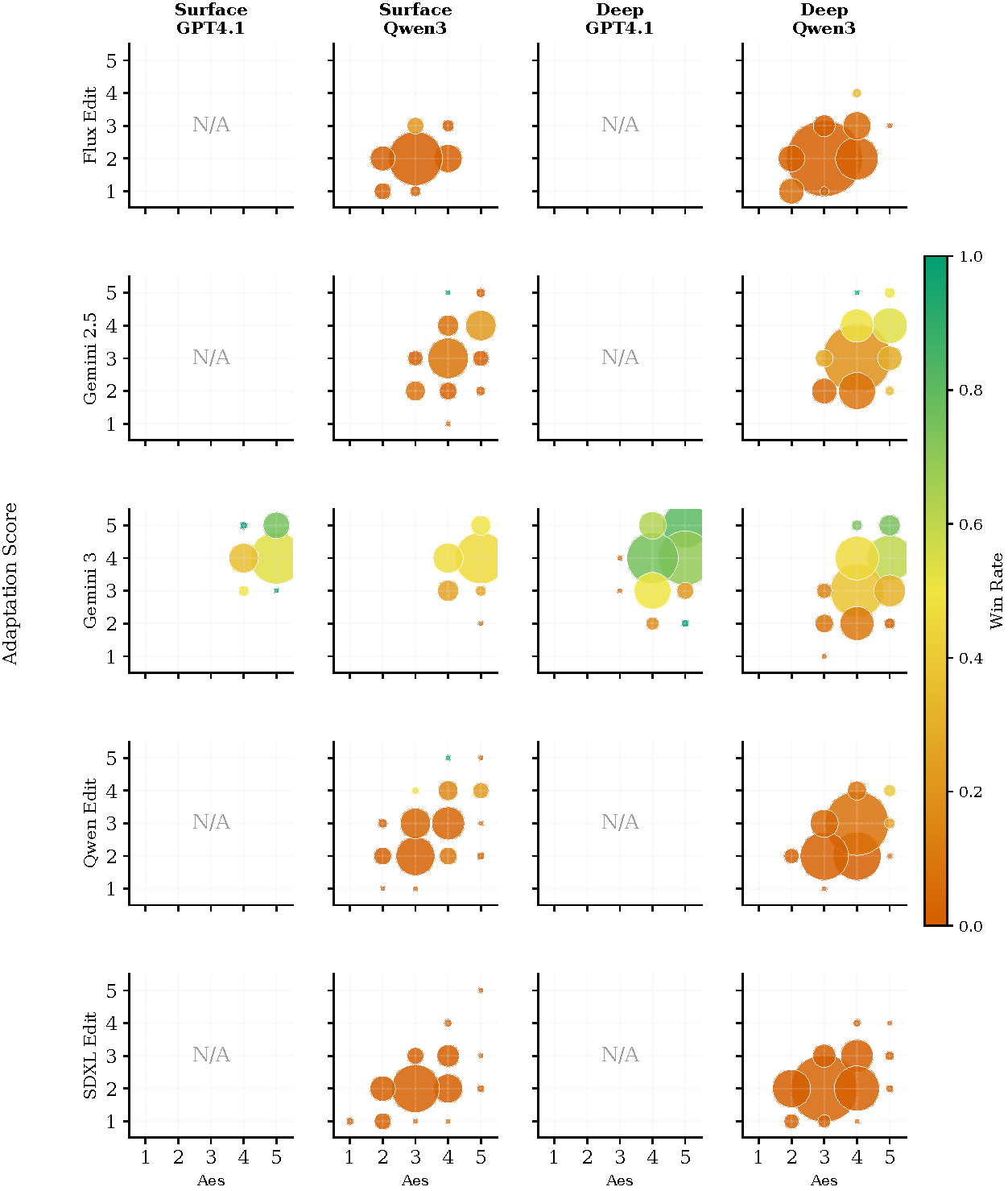
Dataset
MPTc-Bench
Carefully curated aligned poster pairs with rich metadata, filtered from over 4,500 cross-market candidates using perceptual hashing and GLOBE cultural clustering.
582
Aligned poster pairs
34
Target markets
2
Task variants
7
Image editors benchmarked
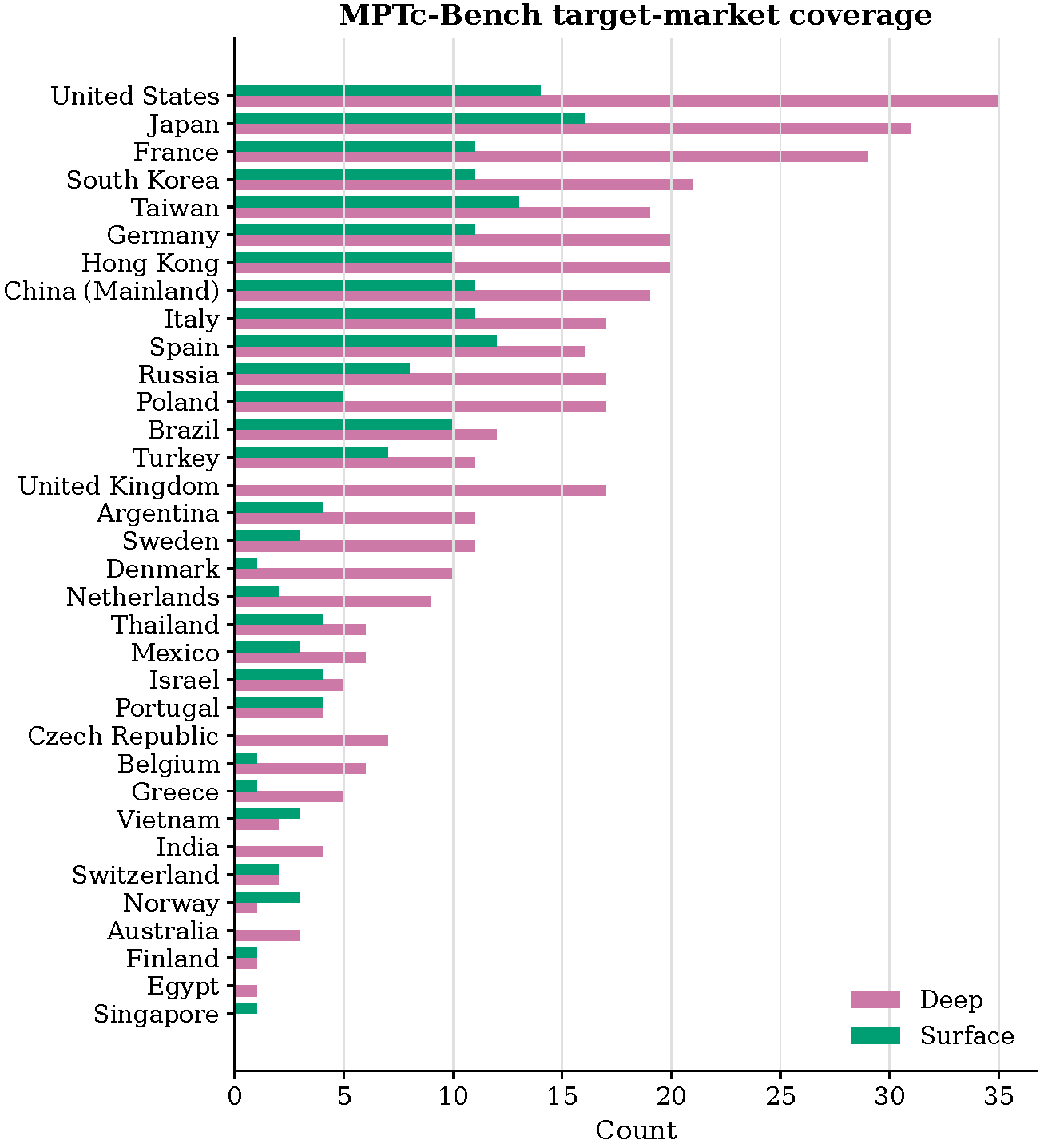
Global coverage: 34 target markets across Asia, Europe, North and South America. Market selection is informed by GLOBE cultural clustering to ensure diversity.
Access the Dataset
from datasets import load_dataset
# Download: https://github.com/minamotooRin/mptc-bench/tree/main/data
import json, urllib.request
for split in ["surface", "deep"]:
url = f"https://raw.githubusercontent.com/minamotooRin/mptc-bench/main/data/mptcbench_{split}.jsonl"
# urllib.request.urlretrieve(url, f"mptcbench_{split}.jsonl")